Subjective phonetic difficulty of English words to Polish learners: does frequency matter?
(a preliminary report on a questionnaire study)
|
|
difficulty index |
||||
|
rank |
0 |
2 |
4 |
6 |
mean |
|
300 |
1.46 (carry) |
1.81 (almost) |
1.91 (appear) |
2.07 (mother) |
1.81 |
|
1300 |
1.50 (belief) |
1.74 (debate) |
2.09 (survive) |
2.90 (author) |
2.06 |
|
2300 |
1.45 (relax) |
2.15 (kingdom) |
1.89 (tired) |
3.19 (southern) |
2.17 |
|
3300 |
1.17 (taxi) |
2.48 (oblige) |
1.76 (server) |
2.07 (youngster) |
1.87 |
|
4300 |
1.67 (defect) |
1.95 (dissolve) |
3.11 (awkward) |
2.07 (coloured) |
2.20 |
|
mean |
1.45 |
2.03 |
2.15 |
2.46 |
2.02 |
The above is a table of mean phonetic difficulty values averaged over 208 questionnaire returns which I collected from IFA students of the first and second years in February. The twenty words in the questionnaire were listed randomly, but were in reality stratified on two dimensions: (1) subjective phonetic difficulty assigned intuitively by the undersigned, and (2) word frequency taken from a large corpus of British English text. The former appears across the top of the table above as 0, 2, 4, 6, i.e. from phonetically easiest to most difficult. The latter is shown down the left-hand side as approximate rank, from the most (300) to the least frequent (4300). Thus, for example, the phonetically easiest of the twenty words, as judged by the 208 respondents, is taxi, with the mean index of 1.17; the hardest is southern - 3.19.
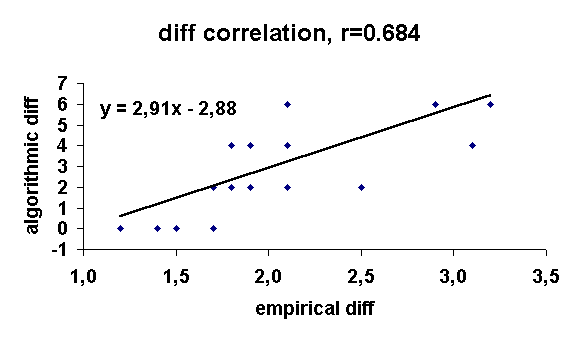
Further inspection of the table reveals that the respondents' difficulty ratings correlate very highly with mine (r=0.684; see below for a scatterplot), as well as that the less common the word is (the higher the rank), the more phonetically difficult it is rated, other things being equal. Interestingly, there is also interaction between the two effects, i.e. the mean difficulty index raises in proportion to the combined effect of my intuitive difficulty judgement and rank, as shown by the shading in the table. All these results are highly reliable and significant statistically.
The results will be analysed and presented in a paper, as well as used in my work on the phonetic difficulty index of a multi-access machine-readable dictionary of English for Polish learners. A more detailed presentation of the methodology and results of the project took place on Thursday, 30th March, in a Phon&Phon meeting.
Let me once again thank all the respondents and phonetics teachers who applied the questionnaire on my behalf.
W.Sobkowiak
2.4.2000
The scatterplot with the best-fitting regression line shows the correlation between the respondents' difficulty ratings and my own intuition.